作者:朱凱
導(dǎo)讀
隨著深度學(xué)習(xí)的不斷發(fā)展,AI模型結(jié)構(gòu)在快速演化,底層計(jì)算硬件技術(shù)更是層出不窮,對于廣大開發(fā)者來說不僅要考慮如何在復(fù)雜多變的場景下有效的將算力發(fā)揮出來,還要應(yīng)對計(jì)算框架的持續(xù)迭代。深度編譯器就成了應(yīng)對以上問題廣受關(guān)注的技術(shù)方向,讓用戶僅需專注于上層模型開發(fā),降低手工優(yōu)化性能的人力開發(fā)成本,進(jìn)一步壓榨硬件性能空間。阿里云機(jī)器學(xué)習(xí)PAI開源了業(yè)內(nèi)較早投入實(shí)際業(yè)務(wù)應(yīng)用的動態(tài)shape深度學(xué)習(xí)編譯器 BladeDISC,本文將詳解 BladeDISC的設(shè)計(jì)原理和應(yīng)用。
BladeDISC是什么
BladeDISC是阿里最新開源的基于MLIR的動態(tài)shape深度學(xué)習(xí)編譯器。
主要特性
· 多款前端框架支持:TensorFlow,PyTorch
· 多后端硬件支持:CUDA,ROCM,x86
· 完備支持動態(tài)shape語義編譯
· 支持推理及訓(xùn)練
· 輕量化API,對用戶通用透明
· 支持插件模式嵌入宿主框架運(yùn)行,以及獨(dú)立部署模式
開源地址:
https://github.com/alibaba/BladeDISC
深度學(xué)習(xí)編譯器的背景
近幾年來,深度學(xué)習(xí)編譯器作為一個(gè)較新的技術(shù)方向異常地活躍,包括老牌一些的TensorFlow XLA、TVM、Tensor Comprehension、Glow,到后來呼聲很高的MLIR以及其不同領(lǐng)域的延伸項(xiàng)目IREE、mlir-hlo等等。能夠看到不同的公司、社區(qū)在這個(gè)領(lǐng)域進(jìn)行著大量的探索和推進(jìn)。
AI浪潮與芯片浪潮共同催生——從萌芽之初到蓬勃發(fā)展
深度學(xué)習(xí)編譯器近年來之所以能夠受到持續(xù)的關(guān)注,主要來自于幾個(gè)方面的原因:
框架性能優(yōu)化在模型泛化性方面的需求
深度學(xué)習(xí)還在日新月異的發(fā)展之中,創(chuàng)新的應(yīng)用領(lǐng)域不斷涌現(xiàn),復(fù)雜多變的場景下如何有效的將硬件的算力充分發(fā)揮出來成為了整個(gè)AI應(yīng)用鏈路中非常重要的一環(huán)。在早期,神經(jīng)網(wǎng)絡(luò)部署的側(cè)重點(diǎn)在于框架和算子庫,這部分職責(zé)很大程度上由深度學(xué)習(xí)框架、硬件廠商提供的算子庫、以及業(yè)務(wù)團(tuán)隊(duì)的手工優(yōu)化工作來承擔(dān)。
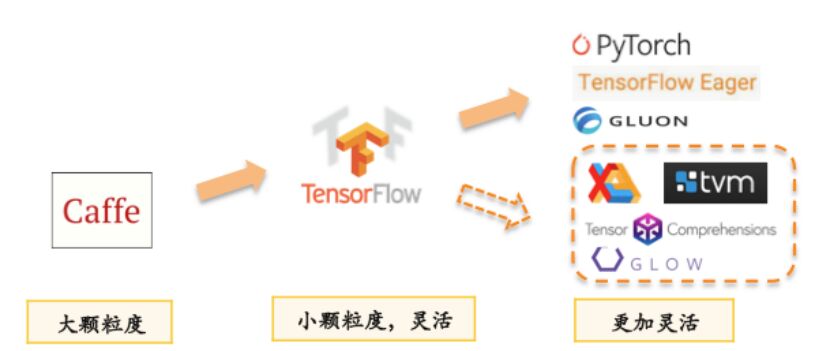
上圖將近年的深度學(xué)習(xí)框架粗略分為三代。一個(gè)趨勢是在上層的用戶API層面,這些框架在變得越來越靈活,靈活性變強(qiáng)的同時(shí)也為底層性能問題提出了更大的挑戰(zhàn)。初代深度學(xué)習(xí)框架類似 Caffe 用 sequence of layer 的方式描述神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu),第二代類似 TensorFlow 用更細(xì)粒度的 graph of operators 描述計(jì)算圖,到第三代類似 PyTorch,TensorFlow Eager Mode 的動態(tài)圖。我們可以看到框架越來越靈活,描述能力越來越強(qiáng),帶來的問題是優(yōu)化底層性能變得越來越困難。業(yè)務(wù)團(tuán)隊(duì)也經(jīng)常需要補(bǔ)充完成所需要的手工優(yōu)化,這些工作依賴于特定業(yè)務(wù)和對底層硬件的理解,耗費(fèi)人力且難以泛化。而深度學(xué)習(xí)編譯器則是結(jié)合編譯時(shí)圖層的優(yōu)化以及自動或者半自動的代碼生成,將手工優(yōu)化的原理做泛化性的沉淀,以替代純手工優(yōu)化帶來的各種問題,去解決深度學(xué)習(xí)框架的靈活性和性能之間的矛盾。
AI框架在硬件泛化性方面的需求
表面上看近些年AI發(fā)展的有目共睹、方興未艾,而后臺的硬件算力數(shù)十年的發(fā)展才是催化AI繁榮的核心動力。隨著晶體管微縮面臨的各種物理挑戰(zhàn)越來越大,芯片算力的增加越來越難,摩爾定律面臨失效,創(chuàng)新體系結(jié)構(gòu)的各種DSA芯片迎來了一波熱潮,傳統(tǒng)的x86、ARM等都在不同的領(lǐng)域強(qiáng)化著自己的競爭力。硬件的百花齊放也為AI框架的發(fā)展帶來了新的挑戰(zhàn)。
而硬件的創(chuàng)新是一個(gè)問題,如何能把硬件的算力在真實(shí)的業(yè)務(wù)場景中發(fā)揮出來則是另外一個(gè)問題。新的AI硬件廠商不得不面臨除了要在硬件上創(chuàng)新,還要在軟件棧上做重度人力投入的問題。向下如何兼容硬件,成為了如今深度學(xué)習(xí)框架的核心難點(diǎn)之一,而兼容硬件這件事,則需要由編譯器來解決。
AI系統(tǒng)平臺對前端AI框架泛化性方面的需求
當(dāng)今主流的深度學(xué)習(xí)框架包括Tensoflow、Pytorch、Keras、JAX等等,幾個(gè)框架都有各自的優(yōu)缺點(diǎn),在上層對用戶的接口方面風(fēng)格各異,卻同樣面臨硬件適配以及充分發(fā)揮硬件算力的問題。不同的團(tuán)隊(duì)常根據(jù)自己的建模場景和使用習(xí)慣來選擇不同的框架,而云廠商或者平臺方的性能優(yōu)化工具和硬件適配方案則需要同時(shí)考慮不同的前端框架,甚至未來框架演進(jìn)的需求。Google利用XLA同時(shí)支持TensorFlow和JAX,同時(shí)其它開源社區(qū)還演進(jìn)出了Torch_XLA,Torch-MLIR這樣的接入方案,這些接入方案目前雖然在易用性和成熟程度等方面還存在一些問題,卻反應(yīng)出AI系統(tǒng)層的工作對前端AI框架泛化性方面的需求和技術(shù)趨勢。
什么是深度學(xué)習(xí)編譯器
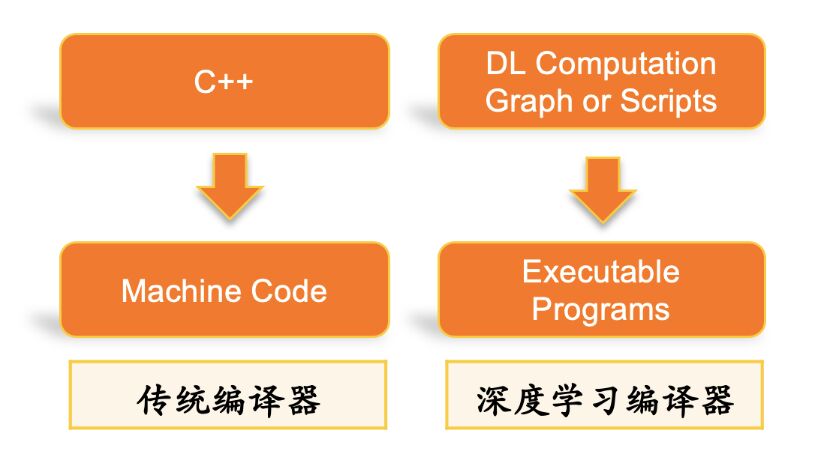
傳統(tǒng)編譯器是以高層語言作為輸入,避免用戶直接去寫機(jī)器碼,而用相對靈活高效的語言來工作,并在編譯的過程中引入優(yōu)化來解決高層語言引入的性能問題,平衡開發(fā)效率與性能之間的矛盾。而深度學(xué)習(xí)編譯器的作用相仿,其輸入是比較靈活的,具備較高抽象度的計(jì)算圖描述,輸出包括CPU、GPU及其他異構(gòu)硬件平臺上的底層機(jī)器碼及執(zhí)行引擎。
傳統(tǒng)編譯器的使命之一是減輕編程者的壓力。作為編譯器的輸入的高級語言往往更多地是描述一個(gè)邏輯,為了便利編程者,高級語言的描述會更加抽象和靈活,至于這個(gè)邏輯在機(jī)器上是否能夠高效的執(zhí)行,往往是考驗(yàn)編譯器的一個(gè)重要指標(biāo)。深度學(xué)習(xí)作為一個(gè)近幾年發(fā)展異常快速的應(yīng)用領(lǐng)域,它的性能優(yōu)化至關(guān)重要,并且同樣存在高層描述的靈活性和抽象性與底層計(jì)算性能之間的矛盾,因此專門針對深度學(xué)習(xí)的編譯器出現(xiàn)了。而傳統(tǒng)編譯器的另外一個(gè)重要使命是,需要保證編程者輸入的高層語言能夠執(zhí)行在不同體系結(jié)構(gòu)和指令集的硬件計(jì)算單元上,這一點(diǎn)也同樣反應(yīng)在深度學(xué)習(xí)編譯器上。面對一個(gè)新的硬件設(shè)備,人工的話不太可能有精力對那么多目標(biāo)硬件重新手寫一個(gè)框架所需要的全部算子實(shí)現(xiàn),深度學(xué)習(xí)編譯器提供中間層的IR,將頂層框架的模型流圖轉(zhuǎn)化成中間層表示IR,在中間層IR上進(jìn)行通用的圖層優(yōu)化,而在后端將優(yōu)化后的IR通用性的生成各個(gè)目標(biāo)平臺的機(jī)器碼。
深度學(xué)習(xí)編譯器的目標(biāo)是針對AI計(jì)算任務(wù),以通用編譯器的方式完成性能優(yōu)化和硬件適配。讓用戶可以專注于上層模型開發(fā),降低用戶手工優(yōu)化性能的人力開發(fā)成本,進(jìn)一步壓榨硬件性能空間。
距離大規(guī)模應(yīng)用面臨的瓶頸問題
深度學(xué)習(xí)編譯器發(fā)展到今天,雖然在目標(biāo)和技術(shù)架構(gòu)方面與傳統(tǒng)編譯器有頗多相似之處,且在技術(shù)方向上表現(xiàn)出了良好的潛力,然而目前的實(shí)際應(yīng)用范圍卻仍然距離傳統(tǒng)編譯器有一定的差距,主要難點(diǎn)包括:
易用性
深度學(xué)習(xí)編譯器的初衷是希望簡化手工優(yōu)化性能和適配硬件的人力成本。然而在現(xiàn)階段,大規(guī)模部署應(yīng)用深度學(xué)習(xí)編譯器的挑戰(zhàn)仍然較大,能夠?qū)⒕幾g器用好的門檻較高,造成這個(gè)現(xiàn)象的主要原因包括:
· 與前端框架對接的問題。不同框架對深度學(xué)習(xí)任務(wù)的抽象描述和API接口各有不同,語義和機(jī)制上有各自的特點(diǎn),且作為編譯器輸入的前端框架的算子類型數(shù)量呈開放性狀態(tài)。如何在不保證所有算子被完整支持的情況下透明化的支持用戶的計(jì)算圖描述,是深度學(xué)習(xí)編譯器能夠易于為用戶所廣泛使用的重要因素之一。
· 動態(tài)shape問題和動態(tài)計(jì)算圖問題。現(xiàn)階段主流的深度學(xué)習(xí)編譯器主要針對特定的靜態(tài)shape輸入完成編譯,此外對包含control flow語義的動態(tài)計(jì)算圖只能提供有限的支持或者完全不能夠支持。而AI的應(yīng)用場景卻恰恰存在大量這一類的任務(wù)需求。這時(shí)只能人工將計(jì)算圖改寫為靜態(tài)或者半靜態(tài)的計(jì)算圖,或者想辦法將適合編譯器的部分子圖提取出來交給編譯器。這無疑加重了應(yīng)用深度學(xué)習(xí)編譯器時(shí)的工程負(fù)擔(dān)。更嚴(yán)重的問題是,很多任務(wù)類型并不能通過人工的改寫來靜態(tài)化,這導(dǎo)致這些情況下編譯器完全無法實(shí)際應(yīng)用。
· 編譯開銷問題。作為性能優(yōu)化工具的深度學(xué)習(xí)編譯器只有在其編譯開銷對比帶來的性能收益有足夠優(yōu)勢的情況下才真正具有實(shí)用價(jià)值。部分應(yīng)用場景下對于編譯開銷的要求較高,例如普通規(guī)模的需要幾天時(shí)間完成訓(xùn)練任務(wù)有可能無法接受幾個(gè)小時(shí)的編譯開銷。對于應(yīng)用工程師而言,使用編譯器的情況下不能快速的完成模型的調(diào)試,也增加了開發(fā)和部署的難度和負(fù)擔(dān)。
· 對用戶透明性問題。部分AI編譯器并非完全自動的編譯工具,其性能表現(xiàn)比較依賴于用戶提供的高層抽象的實(shí)現(xiàn)模版。主要是為算子開發(fā)工程師提供效率工具,降低用戶人工調(diào)優(yōu)各種算子實(shí)現(xiàn)的人力成本。但這也對使用者的算子開發(fā)經(jīng)驗(yàn)和對硬件體系結(jié)構(gòu)的熟悉程度提出了比較高的要求。此外,對于新硬件的軟件開發(fā)者來說,現(xiàn)有的抽象卻又常常無法足夠描述創(chuàng)新的硬件體系結(jié)構(gòu)上所需要的算子實(shí)現(xiàn)。需要對編譯器架構(gòu)足夠熟悉的情況下對其進(jìn)行二次開發(fā)甚至架構(gòu)上的重構(gòu),門檻及開發(fā)負(fù)擔(dān)仍然很高。
魯棒性
目前主流的幾個(gè)AI編譯器項(xiàng)目大多數(shù)都還處于偏實(shí)驗(yàn)性質(zhì)的產(chǎn)品,但產(chǎn)品的成熟度距離工業(yè)級應(yīng)用有較大的差距。這里的魯棒性包含是否能夠順利完成輸入計(jì)算圖的編譯,計(jì)算結(jié)果的正確性,以及性能上避免coner case下的極端badcase等。
性能問題
編譯器的優(yōu)化本質(zhì)上是將人工的優(yōu)化方法,或者人力不易探究到的優(yōu)化方法通過泛化性的沉淀和抽象,以有限的編譯開銷來替代手工優(yōu)化的人力成本。然而如何沉淀和抽象的方法學(xué)是整個(gè)鏈路內(nèi)最為本質(zhì)也是最難的問題。深度學(xué)習(xí)編譯器只有在性能上真正能夠代替或者超過人工優(yōu)化,或者真正能夠起到大幅度降低人力成本作用的情況下才能真正發(fā)揮它的價(jià)值。
然而達(dá)到這一目標(biāo)卻并非易事,深度學(xué)習(xí)任務(wù)大都是tensor級別的計(jì)算,對于并行任務(wù)的拆分方式有很高的要求,但如何將手工的優(yōu)化泛化性的沉淀在編譯器技術(shù)內(nèi),避免編譯開銷爆炸以及分層之后不同層級之間優(yōu)化的聯(lián)動,仍然有更多的未知需要去探索和挖掘。這也成為以MLIR框架為代表的下一代深度學(xué)習(xí)編譯器需要著重思考和解決的問題。
BladeDISC的主要技術(shù)特點(diǎn)
項(xiàng)目最早啟動的初衷是為了解決XLA和TVM當(dāng)前版本的靜態(tài)shape限制,內(nèi)部命名為 DISC (DynamIc Shape Compiler),希望打造一款能夠在實(shí)際業(yè)務(wù)中使用的完備支持動態(tài)shape語義的深度學(xué)習(xí)編譯器。
從團(tuán)隊(duì)四年前啟動深度學(xué)習(xí)編譯器方向的工作以來,動態(tài)shape問題一直是阻礙實(shí)際業(yè)務(wù)落地的嚴(yán)重問題之一。彼時(shí),包括XLA在內(nèi)的主流深度學(xué)習(xí)框架,都是基于靜態(tài)shape語義的編譯器框架。典型的方案是需要用戶指定輸入的shape,或是由編譯器在運(yùn)行時(shí)捕捉待編譯子圖的實(shí)際輸入shape組合,并且為每一個(gè)輸入shape組合生成一份編譯結(jié)果。
靜態(tài)shape編譯器的優(yōu)勢顯而易見,編譯期完全已知靜態(tài)shape信息的情況下,Compiler可以作出更好的優(yōu)化決策并得到更好的CodeGen性能,同時(shí)也能夠得到更好的顯存/內(nèi)存優(yōu)化plan和調(diào)度執(zhí)行plan。然而,其缺點(diǎn)也十分明顯,具體包括:
· 大幅增加編譯開銷。引入離線編譯預(yù)熱過程,大幅增加推理任務(wù)部署過程復(fù)雜性;訓(xùn)練迭代速度不穩(wěn)定甚至整體訓(xùn)練時(shí)間負(fù)優(yōu)化。
· 部分業(yè)務(wù)場景shape變化范圍趨于無窮的,導(dǎo)致編譯緩存永遠(yuǎn)無法收斂,方案不可用。
· 內(nèi)存顯存占用的增加。編譯緩存額外占用的內(nèi)存顯存,經(jīng)常導(dǎo)致實(shí)際部署環(huán)境下的內(nèi)存/顯存OOM,直接阻礙業(yè)務(wù)的實(shí)際落地。
· 人工padding為靜態(tài)shape等緩解性方案對用戶不友好,大幅降低應(yīng)用的通用性和透明性,影響迭代效率。
星空人工智能技術(shù)網(wǎng) 倡導(dǎo)尊重與保護(hù)知識產(chǎn)權(quán)。如發(fā)現(xiàn)本站文章存在版權(quán)等問題,煩請30天內(nèi)提供版權(quán)疑問、身份證明、版權(quán)證明、聯(lián)系方式等發(fā)郵件至1851688011@qq.com我們將及時(shí)溝通與處理。!:首頁 > 新聞 » 阿里 BladeDISC 深度學(xué)習(xí)編譯器正式開源