AI數據區別于傳統數據的三個特點
第一個特點是數據組織的無標準。像傳統大數據基本上是一個大寬表,在大寬表之上,通過SQL來進行ETL就能解決絕大多數問題。但AI數據組織是沒有標準的。
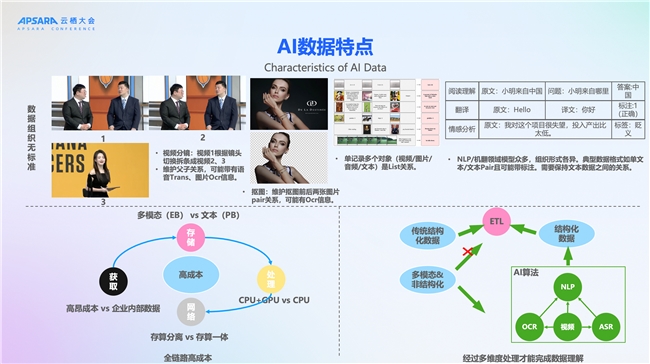
舉四個例子。第一個是視頻,視頻在處理之前,一般都要進行拆條,拆解成子視頻,比如說定長拆條,或者通過關鍵幀,或者通過場景來拆條。拆完以后,這一條記錄要保存父視頻和子視頻的關系,同時這個視頻里面可能還有音軌、標題、字幕等等一些信息。
第二個例子就是用于摳圖場景的圖片數據,需要維護這個圖片的映射關系。
第三個例子是一個多輪對話的例子。這個多輪對話里面,可能單條記錄要包含多個模態信息,文本、視頻、音頻等等,他們之間是一個list關系。
第四個例子就是文本,數據組織形式更加復雜,不同的場景還是不一樣的。需要在單條記錄里就能涵蓋這些所有的AI數據的組織,這些例子可以看出來AI數據組織是沒有標準的。
第二個特點是AI數據相對于傳統的數據來說成本比較高,從數據的獲取角度,需要去做大量的人工標注,還有獲取有版權的數據,相對于企業內部的結構化數據成本非常高。還有數據存儲也需要消耗較大的成本,多模態數據跟傳統數據的存儲成本差異是顯而易見的。第三個是數據處理,除了CPU以外還需要GPU的處理。最后是網絡,多模態數據一般分散存儲在各個地域的對象存儲引擎里,計算引擎也是分散在各處,在處理、訓練的時候,就需要去跨地域的進行拖拉數據。所以全鏈路成本就比較高。
第三個特點就是理解成本也比較高。傳統數據簡單進行ETL就能夠完全理解。但是在AI數據這方面,理解就比較復雜。以視頻為例,至少包含視覺、音頻、文本三方面的信息。
文本需要一些文本的模型去進行理解;視覺信息我們需要去抽幀,抽完幀以后通過一些OCR的手段來去識別文本,然后再進行理解;音頻需要提取音軌然后通過ASR的手段提取文本,最后再進行一些處理。
所以相較于傳統大數據,AI數據還是有很多不同。
基于MaxCompute來構建數據處理平臺
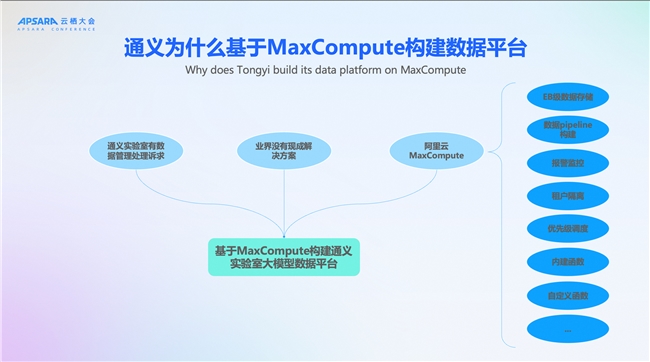
為什么通義實驗室要基于MaxCompute來構建數據平臺?首先,通義實驗室有數據統一管理及處理的訴求。通義實驗室有通義千問、通義萬相以及多個領域模型。數據需要進行統一管理,只有統一管理才能更高效的流轉。
通義實驗室是在2020年去開始構建這個數據平臺。當時通義實驗室的各個算法團隊還在孵化階段,業界當時沒有成熟的解決方案。但是通義對AI數據的管理、處理的訴求是非常明確的,阿里云MaxCompute能夠滿足通義實驗室的需求,比如支持EB級的數據存儲,可以基于DataWorks構建數據處理pipeline,海量豐富的內建UDF,也支持用各種語言python、java等開發我們自己的自定義函數。
在這樣的背景下,我們選擇基于MaxCompute來構建了通義實驗室的大模型數據平臺。
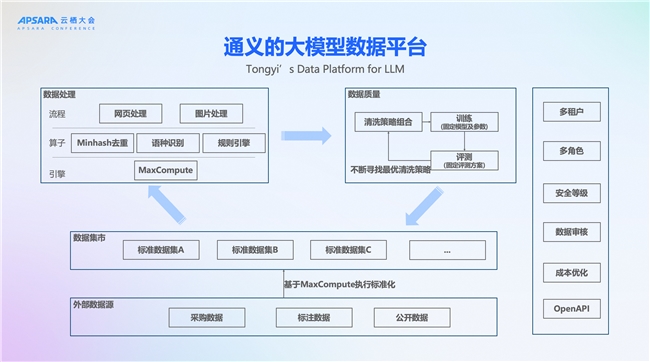
這個是通義實驗室大模型數據平臺的基本架構。首先我們的外部數據包含了采購的數據,人工標注的數據,還有一些公開可下載的數據。
拿到這些數據以后,第一步操作就是基于MaxCompute平臺進行標準化。執行標準化了以后,那么所有的通義實驗室的算法同學來看到這個數據,不需要過多的理解就能知道數據的含義。通過這樣的方式加速提升了數據的流動效率。
在標準化之后,我們構建了一個數據集市,這個數據集市上面有一些比較原始的數據,也有一些高質量的數據。數據集市之上,就是基于MaxCompute去構建的數據處理的pipeline。
首先我們沉淀了海量的算子,比如說Minhash去重算子,語種識別的算子等等。在這各種算子之上,我們再構建了各種的處理的pipeline,包括千問的網頁處理的pipeline, 還有圖片處理的pipeline等。
在數據處理之后,這個數據往往不能夠直接去用到千萬和萬相的訓練中,因為處理完以后的數據,我們需要保障其滿足一定質量要求。所以我們構建了一個清洗-訓練-評測的數據飛輪,去不斷尋找最優的清洗策略,最終數據質量達到一定標準后以后,會把這個數據提供給通義千問和通義萬相,這個數據也會沉淀下來到我們的數據集市。
以上就是通義實驗室的數據管理及處理解決方案,用于提供通義千萬和通義萬相的訓練數據。
星空人工智能技術網 倡導尊重與保護知識產權。如發現本站文章存在版權等問題,煩請30天內提供版權疑問、身份證明、版權證明、聯系方式等發郵件至1851688011@qq.com我們將及時溝通與處理。!:首頁 > 星空人工智能產業 > AI大模型 » 通義實驗室基于阿里云 MaxCompute 進行大模型數據管理及處理