大語(yǔ)言模型的快速發(fā)展對(duì)訓(xùn)練和推理技術(shù)帶來(lái)了更高的要求,基于飛槳框架3.0版本打造的PaddleNLP大語(yǔ)言模型套件,通過(guò)極致的全流程優(yōu)化,為開(kāi)發(fā)者提供從組網(wǎng)開(kāi)發(fā)、預(yù)訓(xùn)練、精調(diào)對(duì)齊、模型壓縮以及推理部署的一站式解決方案。
產(chǎn)品亮點(diǎn)
1. 大模型自動(dòng)并行,千億模型訓(xùn)推全流程開(kāi)箱即用
基于飛槳框架3.0版本,通過(guò)統(tǒng)一的分布式表示結(jié)合自動(dòng)并行技術(shù),大幅簡(jiǎn)化了組網(wǎng)開(kāi)發(fā)的復(fù)雜性,分布式核心代碼量減少50%以上,全分布式策略支持的組網(wǎng)支持Llama 3.1 405B模型開(kāi)箱即用,同時(shí)預(yù)置了80多個(gè)主流模型的訓(xùn)練-壓縮-推理的全流程方案,以滿足不同場(chǎng)景需求。
2. 大模型訓(xùn)推一體,提供產(chǎn)業(yè)級(jí)高性能精調(diào)與對(duì)齊方案
基于飛槳框架獨(dú)有的FlashMask高性能變長(zhǎng)注意力掩碼計(jì)算機(jī)制,結(jié)合Zero Padding零填充數(shù)據(jù)流優(yōu)化技術(shù),可最大程度減少無(wú)效數(shù)據(jù)填充帶來(lái)計(jì)算資源浪費(fèi),顯著提升精調(diào)和對(duì)齊性能。以Llama 3.1 8B模型為例,相比LLaMA-Factory方案,性能提升了1.2倍,單機(jī)即可完成128K長(zhǎng)文的SFT/DPO。借助飛槳訓(xùn)推一體特性,提供產(chǎn)業(yè)級(jí)的RLHF方案,PPO采樣可復(fù)用推理加速算子,訓(xùn)練吞吐提升達(dá)2.1倍。
3. 大模型多硬件適配,30余接口低成本適配實(shí)現(xiàn)軟硬協(xié)同優(yōu)化
基于飛槳插件式松耦合統(tǒng)一硬件適配方案(CustomDevice),僅需適配30余個(gè)接口,即可實(shí)現(xiàn)大模型的基礎(chǔ)適配,低成本完成訓(xùn)練-壓縮-推理全流程;PaddleNLP目前一站式支持英偉達(dá) GPU、昆侖芯 XPU、昇騰NPU、燧原 GCU 和海光 DCU 等多款芯片的大模型訓(xùn)練和推理,依托框架多種算子接入模式和自動(dòng)并行調(diào)優(yōu)等技術(shù),便捷實(shí)現(xiàn)框架與芯片間軟硬協(xié)同的性能優(yōu)化。
歡迎開(kāi)發(fā)者前往開(kāi)源項(xiàng)目主頁(yè)直接體驗(yàn):

亮點(diǎn)一:大模型自動(dòng)并行,千億級(jí)模型訓(xùn)推全流程開(kāi)箱即用1. 自動(dòng)并行降低開(kāi)發(fā)成本,80+模型開(kāi)箱即用
本次PaddleNLP 3.0升級(jí)總計(jì)涵蓋了80+業(yè)界主流的開(kāi)源大語(yǔ)言模型,參數(shù)量覆蓋從0.5B到405B不等,能夠靈活滿足各種場(chǎng)景下的用戶需求。借助飛槳3.0版本框架的最新特性,通過(guò)統(tǒng)一的分布式表示和自動(dòng)并行技術(shù),大幅簡(jiǎn)化了組網(wǎng)開(kāi)發(fā)的復(fù)雜性。分布式核心代碼量減少50%以上,全分布式策略支持的組網(wǎng)使得Llama 3.1 405B的SFT與PEFT功能開(kāi)箱即用。
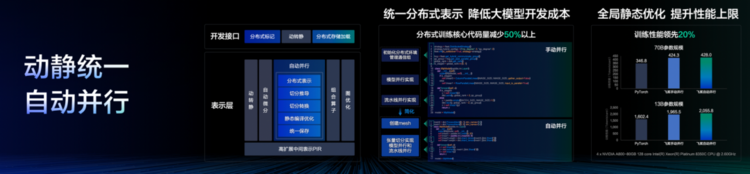
動(dòng)靜統(tǒng)一、自動(dòng)并行
2. 訓(xùn)壓推全流程貫通,模型秒級(jí)保存與穩(wěn)定恢復(fù)
在PaddleNLP本次升級(jí)中重點(diǎn)強(qiáng)化大語(yǔ)言模型訓(xùn)練-壓縮-推理的全流程開(kāi)發(fā)能力,基于飛槳框架3.0版本全新設(shè)計(jì)的一站式開(kāi)發(fā)體驗(yàn),大幅降低學(xué)習(xí)和使用成本。
分布式訓(xùn)練:基于Fleet API實(shí)現(xiàn)了全并行策略支持的高性能組網(wǎng),覆蓋預(yù)訓(xùn)練、精調(diào)(SFT/PEFT)和對(duì)齊(RLHF/DPO)三個(gè)環(huán)節(jié)的主流算法,相比HuggingFace Transformers僅支持?jǐn)?shù)據(jù)并行的組網(wǎng)實(shí)現(xiàn),飛槳的組網(wǎng)原生支持張量并行和流水線并行,在低資源精調(diào)和長(zhǎng)文訓(xùn)練場(chǎng)景中,具備更高的性能上限和可擴(kuò)展性;
模型壓縮:基于PaddleSlim提供的多種大語(yǔ)言模型Post Training Quantization技術(shù),提供WAC(權(quán)重/激活/緩存)靈活可配的量化能力,與Paddle Inference深度聯(lián)動(dòng),保障壓縮后的模型均能利用高性能低比特算子進(jìn)行推理。
推理部署:基于FastDeploy全場(chǎng)景部署工具,提供了面向服務(wù)器場(chǎng)景的高性能推理服務(wù),支持動(dòng)態(tài)插入、流式輸出、多硬件部署等功能。
業(yè)界方案在不同并行策略和不同結(jié)點(diǎn)數(shù)量下模型保存的Checkpoint格式不統(tǒng)一,模型量化和推理部署使用時(shí)需引入復(fù)雜切分和合并過(guò)程,保存和恢復(fù)時(shí)間長(zhǎng)。針對(duì)這一系列問(wèn)題,PaddleNLP設(shè)計(jì)了Unified Checkpoint大模型存儲(chǔ)方案,突破了以下三個(gè)技術(shù)瓶頸:
統(tǒng)一模型存儲(chǔ)協(xié)議,在模型壓縮、動(dòng)轉(zhuǎn)靜、推理部署等環(huán)節(jié)中無(wú)需引入額外的參數(shù)合并流程。
內(nèi)置參數(shù)自適應(yīng)切分與合并功能,恢復(fù)訓(xùn)練時(shí)并行策略或者結(jié)點(diǎn)數(shù)量變化時(shí)可自動(dòng)完成切分與合并,精準(zhǔn)還原數(shù)據(jù)流狀態(tài)。
支持異步保存與快速恢復(fù),結(jié)合存儲(chǔ)參數(shù)多進(jìn)程均勻讀寫(xiě)分配,實(shí)現(xiàn)秒級(jí)保存與比特穩(wěn)定快速恢復(fù)。
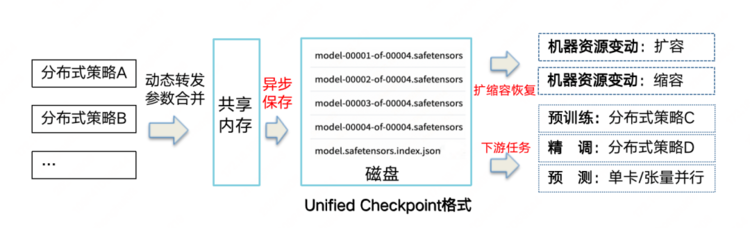
Unified Checkpoint模型參數(shù)存儲(chǔ)示例圖

亮點(diǎn)二:大模型訓(xùn)推一體,提供高性能產(chǎn)業(yè)級(jí)的精調(diào)與對(duì)齊解決方案1. 精調(diào)對(duì)齊性能極致優(yōu)化,支持128K長(zhǎng)上下文訓(xùn)練
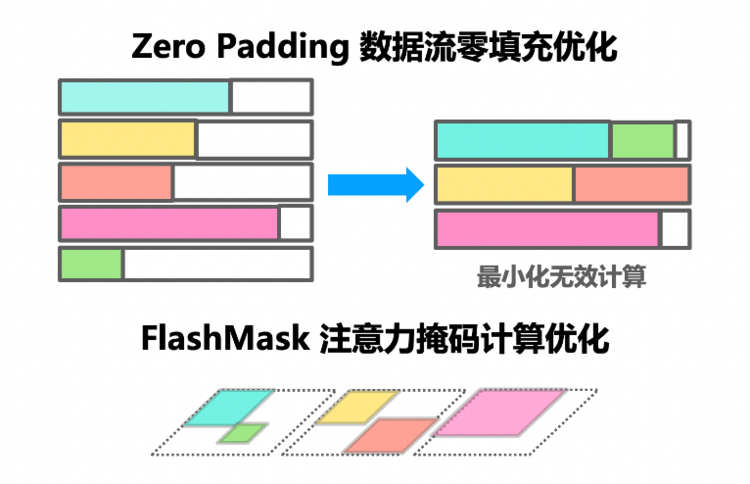
在精調(diào)和對(duì)齊訓(xùn)練中為業(yè)界普遍采用定長(zhǎng)Padding策略解決數(shù)據(jù)長(zhǎng)度不一的問(wèn)題,該做法隨著數(shù)據(jù)集長(zhǎng)度分布差異增大,無(wú)效的Padding計(jì)算也會(huì)同步增加,繼而導(dǎo)致訓(xùn)練時(shí)間增長(zhǎng)。針對(duì)這一問(wèn)題,飛槳框架獨(dú)有FlashMask高性能變長(zhǎng)注意力掩碼計(jì)算結(jié)合PaddleNLP中Zero Padding零填充數(shù)據(jù)流優(yōu)化技術(shù),通過(guò)分組貪心的數(shù)據(jù)填充策略,可最大程度消除無(wú)效Padding的比例。
同時(shí),ZeroPadding+FlashMask稀疏計(jì)算的特性也大幅減少了顯存開(kāi)銷,使精調(diào)訓(xùn)練代碼無(wú)縫從8K擴(kuò)展到128K的長(zhǎng)文訓(xùn)練。
綜合上述優(yōu)化,相比LLaMA-Factory,PaddleNLP在SFT環(huán)節(jié)性能提升120%,DPO環(huán)節(jié)性能提升130%~240%,大幅降低了大模型精調(diào)和對(duì)齊環(huán)節(jié)所需的計(jì)算成本。
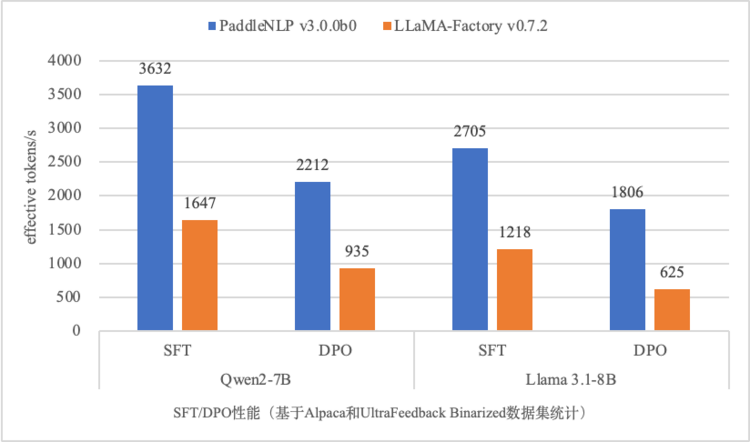
SFT/DPO訓(xùn)練有效吞吐性能對(duì)比
2. 訓(xùn)推一體框架特性加速RLHF訓(xùn)練效率
人類反饋強(qiáng)化學(xué)習(xí)(RLHF)通過(guò)不斷接收人類對(duì)于模型行為的直接評(píng)價(jià)或示例指導(dǎo),促使模型效果逐漸逼近人類預(yù)期的行為模式。然而,多樣化的樣本導(dǎo)致待對(duì)齊模型出現(xiàn)獎(jiǎng)勵(lì)信號(hào)互斥和策略更新程度難以平衡的現(xiàn)象,進(jìn)而導(dǎo)致模型訓(xùn)練時(shí)波動(dòng)幅度大且收斂速度慢,多模型生成和訓(xùn)練容易占用顯存大,訓(xùn)練速度慢。針對(duì)這一系列問(wèn)題,PaddleNLP基于飛槳訓(xùn)推一體框架特性和多多種策略結(jié)合的來(lái)解決:
訓(xùn)推一體:依托飛槳框架訓(xùn)推一體特性,在Policy模型采樣生成復(fù)用推理高性能融合算子,使RLHF訓(xùn)練加速 2.1 倍。
顯存優(yōu)化:基于飛槳原生的張量并行/流水線并行能力,結(jié)合Offload訓(xùn)練模式控制顯存占用,單機(jī)即可完成訓(xùn)練百億級(jí)別PPO訓(xùn)練。
策略優(yōu)化:支持優(yōu)勢(shì)函數(shù)平滑、EMA參數(shù)策略,提升模型訓(xùn)練穩(wěn)定性。

綜合上述優(yōu)化,以LLaMA-7B模型為例,PaddleNLP的PPO訓(xùn)練性能達(dá)Beaver框架的3.2倍。
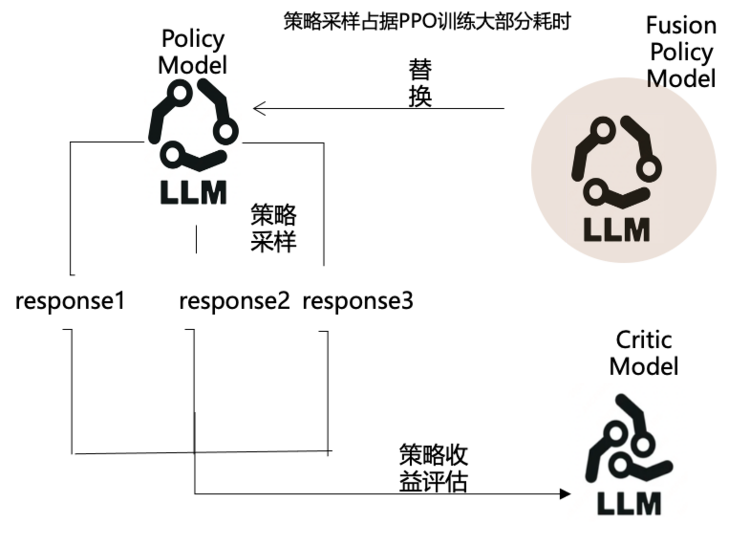
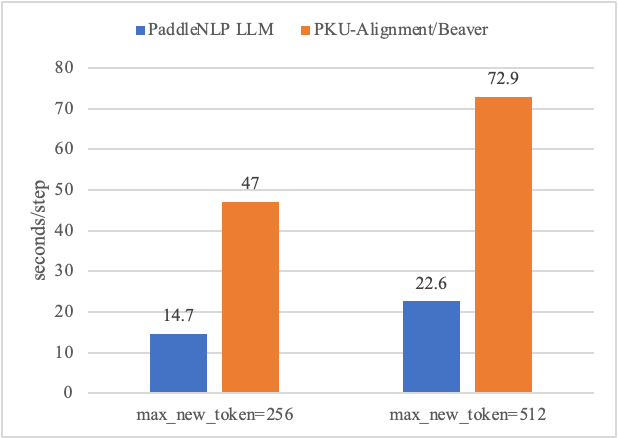
RLHF訓(xùn)練策略&RLHF PPO訓(xùn)練速度對(duì)比

亮點(diǎn)三:大模型多硬件適配,30余接口低成本適配實(shí)現(xiàn)軟硬協(xié)同優(yōu)化
基于飛槳框架3.0發(fā)布的大模型多硬件適配技術(shù),通過(guò)插件式軟硬件松耦合的分層設(shè)計(jì),可以低成本完成芯片的大模型基礎(chǔ)適配和軟硬協(xié)同優(yōu)化,其具備以下特點(diǎn):
硬件適配簡(jiǎn)捷高效:不同硬件僅需適配30余接口,即可全面支持大模型訓(xùn)壓推。
基礎(chǔ)算子體系完備:通過(guò)基礎(chǔ)算子體系,減少硬件適配所需開(kāi)發(fā)的算子數(shù)量。
大模型性能極致優(yōu)化:支持算子融合、顯存復(fù)用等方式實(shí)現(xiàn)高效算子流水編排,極致顯存復(fù)用優(yōu)化。
硬件編譯接入自動(dòng)優(yōu)化:支持通過(guò)神經(jīng)網(wǎng)絡(luò)編譯器代碼后端 CodeGen 的方式接入,實(shí)現(xiàn)多硬件后端的算子生成與性能優(yōu)化。
PaddleNLP目前一站式支持英偉達(dá) GPU、昆侖芯 XPU、昇騰 NPU、燧原 GCU 和海光 DCU 等多款芯片的大模型訓(xùn)練和推理,依托框架多種算子接入和適配模式,以及自動(dòng)并行調(diào)優(yōu)等技術(shù),便捷實(shí)現(xiàn)框架與芯片軟硬協(xié)同的性能優(yōu)化。

飛槳大模型多硬件適配
當(dāng)前PaddleNLP 3.0在支持英特爾CPU和英偉達(dá)GPU的硬件基礎(chǔ)上,針對(duì)Llama類模型結(jié)構(gòu)已適配了昆侖芯XPU、昇騰NPU、海光DCU以及燧原GCU等國(guó)產(chǎn)硬件的訓(xùn)練和推理,只需要一行代碼即可輕松切換硬件,歡迎與生態(tài)伙伴一起共建更多開(kāi)源大模型的多硬件支持!


精彩課程預(yù)告
為了幫助您迅速且深入地了解PaddleNLP 3.0,并熟練掌握實(shí)際操作技巧,百度高級(jí)研發(fā)工程師將在8月15日(周四)19:00,為您詳細(xì)解讀從組網(wǎng)開(kāi)發(fā)、預(yù)訓(xùn)練、精調(diào)對(duì)齊、模型壓縮以及推理部署的一站式解決方案。
星空人工智能技術(shù)網(wǎng) 倡導(dǎo)尊重與保護(hù)知識(shí)產(chǎn)權(quán)。如發(fā)現(xiàn)本站文章存在版權(quán)等問(wèn)題,煩請(qǐng)30天內(nèi)提供版權(quán)疑問(wèn)、身份證明、版權(quán)證明、聯(lián)系方式等發(fā)郵件至1851688011@qq.com我們將及時(shí)溝通與處理。!:首頁(yè) > 星空人工智能產(chǎn)業(yè) > AI大模型 » PaddleNLP 3.0重磅發(fā)布:開(kāi)箱即用的產(chǎn)業(yè)級(jí)大語(yǔ)言模型開(kāi)發(fā)利器