作者:石浪、滿神
近日,阿里巴巴投稿的論文《PICASSO: Unleashing the Potential of GPU-centric Training for Wide-and-deep Recommender Systems》被數(shù)據(jù)庫和數(shù)據(jù)挖掘方向CCF-A類國際三大頂會之一的ICDE 2022 (International Conference on Data Engineering) 接收。ICDE 2022 將于今年5月9日至5月13日在馬來西亞吉隆坡線上召開,屆時將匯集工業(yè)級和學(xué)術(shù)界的頂級學(xué)者共同探討數(shù)據(jù)密集型的系統(tǒng)和應(yīng)用相關(guān)的熱點問題。此次論文入選,意味著阿里云機(jī)器學(xué)習(xí)平臺PAI自研的面向工業(yè)級稀疏模型的高性能訓(xùn)練框架(PAI-HybridBackend)達(dá)到了世界先進(jìn)水平,得到了業(yè)界的廣泛認(rèn)可。
為了回饋社區(qū)并推動技術(shù)進(jìn)步,阿里云機(jī)器學(xué)習(xí)平臺PAI已經(jīng)將HybridBackend框架開源, 歡迎大家試用和技術(shù)共建。
開源地址:https://github.com/alibaba/HybridBackend
背景
以搜索,推薦,廣告業(yè)務(wù)為主要應(yīng)用的稀疏模型訓(xùn)練系統(tǒng)一直是學(xué)界和業(yè)界研究的研究熱點之一。相比于計算機(jī)視覺(CV)和自然語言處理(NLP)為代表的稠密模型訓(xùn)練,稀疏模型針對離散型特征(以categorical ID作為訓(xùn)練數(shù)據(jù))使用的Embedding特征表達(dá)有著百GB至數(shù)十TB級別的內(nèi)存占用消耗(比普通的CV, NLP模型參數(shù)高出一到兩個數(shù)量級), 從而突破了單機(jī)的內(nèi)存容量限制,需要基于分布式系統(tǒng)的訓(xùn)練方案。
早期的此類分布式任務(wù)由于模型結(jié)構(gòu)相對簡單并且更新迭代緩慢,往往采用定制化的參數(shù)服務(wù)器(Parameter Server, PS)系統(tǒng)在大規(guī)模的CPU集群上進(jìn)行訓(xùn)練。隨著Tensorflow為代表的通用機(jī)器學(xué)習(xí)編程框架的出現(xiàn),以及深度神經(jīng)網(wǎng)絡(luò)(DNN)在推薦類模型上的流行(deep recommender systems),業(yè)界逐漸轉(zhuǎn)向基于通用機(jī)器學(xué)習(xí)編程框架(TensorFlow, PyTorch等)來進(jìn)行模型的端到端訓(xùn)練和推理,但是此時依然以參數(shù)服務(wù)器(PS)和大規(guī)模CPU集群作為訓(xùn)練的范式和基礎(chǔ)設(shè)施。
面臨挑戰(zhàn)
近年來,隨著稀疏模型對算力日益增長的需求(比如Attention等結(jié)構(gòu)的加入), CPU集群必須不斷擴(kuò)大集群規(guī)模來滿足訓(xùn)練的時效需求,這同時也帶來了不斷上升的資源成本以及實驗的調(diào)試成本。以NVIDIA GPU為代表的加速器(accelerator)則彌補(bǔ)了CPU設(shè)備單位成本算力低下的劣勢,在CV,NLP等算力需求大的訓(xùn)練任務(wù)上的應(yīng)用已經(jīng)成為行業(yè)共識。然而實踐證明,如果只是簡單地將PS訓(xùn)練范式中的worker從CPU設(shè)備替換為GPU設(shè)備,并不能有效地提升訓(xùn)練任務(wù)的吞吐,通過profiling GPU的使用率,發(fā)現(xiàn)大量的GPU算力資源被閑置浪費。這說明相比與CV, NLP類任務(wù),稀疏模型訓(xùn)練有著自身的模型結(jié)構(gòu)和訓(xùn)練數(shù)據(jù)的特性,使得傳統(tǒng)的PS訓(xùn)練范式不能有效地發(fā)揮出GPU設(shè)備的優(yōu)勢。以深度推薦系統(tǒng)經(jīng)典的Wide and Deep模型結(jié)構(gòu)和Tensorflow框架為例, 我們分析并總結(jié)了在PS架構(gòu)下使用GPU設(shè)備訓(xùn)練的兩個問題。
變化的硬件資源瓶頸
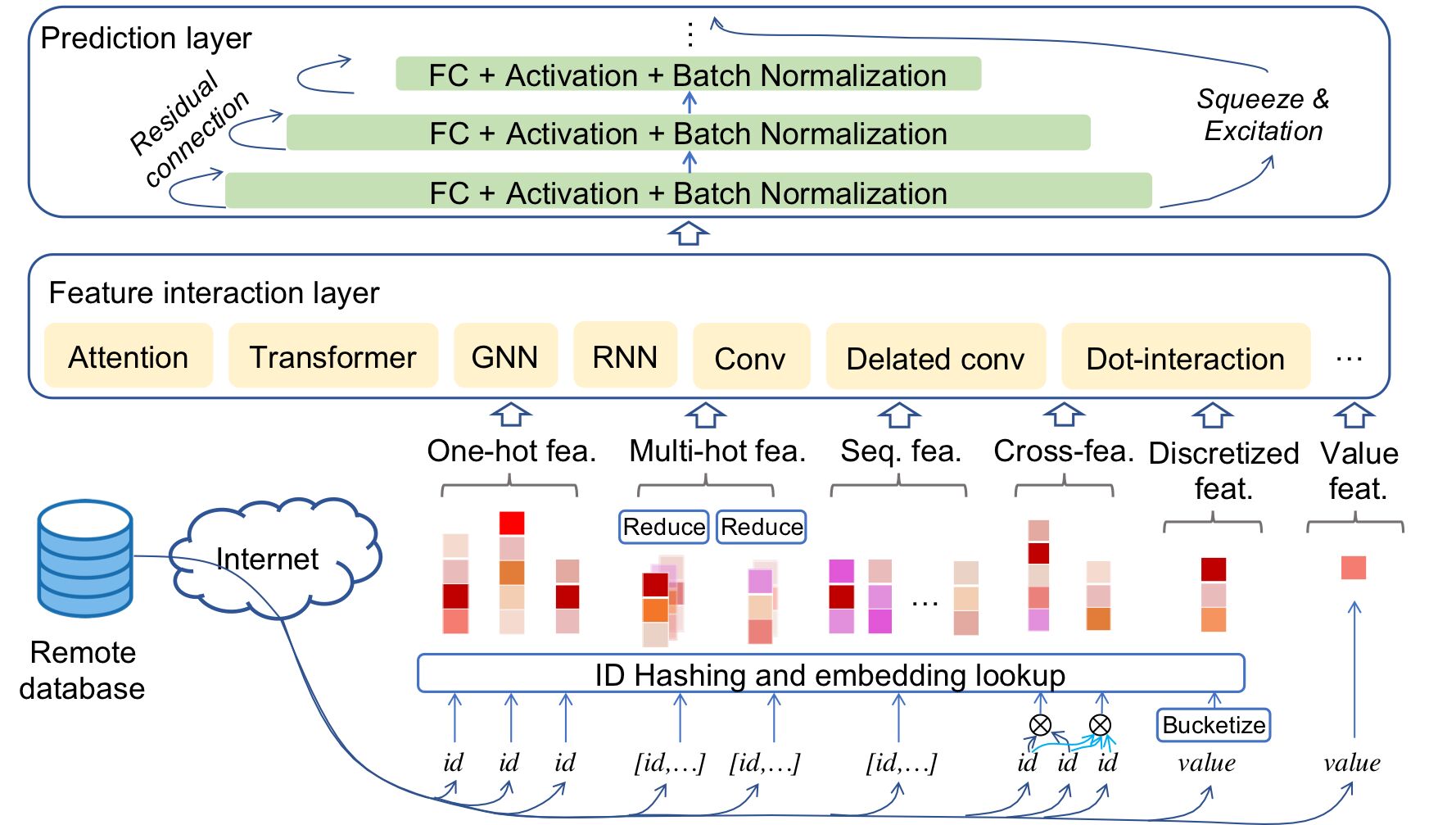
從上圖的Wide and Deep模型結(jié)構(gòu)可以看出,稀疏訓(xùn)練主要由Embedding階段, 特征交叉(feature interation)階段和多層感知器(MLP)階段組成,其中Embedding階段在PS范式的訓(xùn)練下占據(jù)了至少50%以上的訓(xùn)練時間。
經(jīng)過分析發(fā)現(xiàn),Embedding階段的算子主要以訪存密集型(memory access intensive)和通信密集型的算子(communication intensive)為主,主要需要的硬件資源是內(nèi)存和網(wǎng)絡(luò)的帶寬,而后兩個階段的算子則是計算密集型的算子占主導(dǎo), 需要的資源是算力。這意味著在PS的范式訓(xùn)練下,任何一個階段都有可能存在某一種硬件資源成為瓶頸而其他硬件資源被浪費的現(xiàn)象。以GPU的算力資源為例,我們觀察GPU使用率(SM Util)在不同的訓(xùn)練階段之間呈現(xiàn)脈沖式變化(pulse)。

算子細(xì)碎化(fragmentation)
生產(chǎn)實際中的模型往往擁有上百路的Embedding特征查詢,每一路的特征查詢在Tensorflow內(nèi)都會調(diào)用數(shù)十個算子操作(operations)。TensorFlow的引擎在調(diào)度上千級別的大量的算子操作需要額外的CPU線程開銷; 對于GPU設(shè)備來說, 過多的CUDA kernel提交到流處理器上(Tensorflow下每個GPU設(shè)備只有一個stream抽象)造成了GPU Stream Multiprocessor (SM)的調(diào)度開銷,同時每個算子處理數(shù)據(jù)的并發(fā)度又不高,從而很難打滿GPU的計算單元。類似的問題在CV,NLP等稠密模型的訓(xùn)練中也有涉及,一般采用基于編譯技術(shù)的優(yōu)化手段進(jìn)行算子合并。在Wide and Deep模型這樣的稀疏場景下,Embedding階段的這些算子又往往具有dynamic shape的特點,在Tensorflow靜態(tài)構(gòu)圖階段無法獲取準(zhǔn)確的算子尺寸進(jìn)行優(yōu)化,導(dǎo)致類似Tensorflow-XLA等技術(shù)在此類場景下沒有明顯的收益。
這些問題說明,想要發(fā)揮出GPU等高性能硬件資源的極致性價比,提高單位成本下的訓(xùn)練吞吐,就必須設(shè)計新的訓(xùn)練框架。據(jù)我們了解,擁有大型搜索,廣告,推薦業(yè)務(wù)的國內(nèi)外企業(yè)以及硬件廠商都在著手進(jìn)行新框架的研發(fā),比如NVIDIA的Merlin-HugeCTR[1]等,然而集團(tuán)內(nèi)云上集群普遍部署的是通用計算節(jié)點,且集群上需要執(zhí)行多種異構(gòu)的任務(wù),換用專用硬件是很昂貴且不切實際的。基于這種實際需求,我們推出了HybridBackend,同時能夠適應(yīng)集團(tuán)內(nèi)多元化且不斷演進(jìn)的稀疏模型技術(shù)。下文中我們將簡要介紹HybridBackend背后的系統(tǒng)架構(gòu)設(shè)計和技術(shù)亮點。
應(yīng)對破局:HybridBackend的系統(tǒng)架構(gòu)
傳統(tǒng)的參數(shù)服務(wù)器(PS)訓(xùn)練范式,體現(xiàn)的是通過擴(kuò)展硬件數(shù)量來適應(yīng)模型訓(xùn)練規(guī)模的思路,而我們的系統(tǒng)則是同時考慮到了硬件和軟件(模型)兩個層面的特點而做到協(xié)同設(shè)計。高性能GPU集群的硬件特性決定了基本的訓(xùn)練范式,而稀疏模型本身的結(jié)構(gòu)特點和數(shù)據(jù)分布帶來的問題則通過更精細(xì)的系統(tǒng)優(yōu)化手段來解決。
利用大Batch Size進(jìn)行同步訓(xùn)練
因為GPU設(shè)備相對于CPU帶來的巨大的算力提升,以往需要上百臺CPU節(jié)點的集群可以用幾十臺機(jī)器的GPU集群來代替。要保持相同的總訓(xùn)練規(guī)模,同時提升單個GPU節(jié)點上的資源利用率,提升單個GPU worker上的batch size成為必然的選項,同時因為集群規(guī)模的縮小,可以通過同步訓(xùn)練的方式來有效避免過期梯度(staleness)從而提升模型訓(xùn)練的精度。相對于CPU設(shè)備之間通過PCIe以及TCP進(jìn)行網(wǎng)絡(luò)通信,高性能的GPU集群在單個節(jié)點內(nèi)的多個GPU設(shè)備之間往往配備了高速的網(wǎng)絡(luò)互連(NVLink, NVSwitch), 這些高速連接的帶寬通常是TCP網(wǎng)絡(luò)帶寬的數(shù)百倍(第一代NVLINK標(biāo)定達(dá)到300GB/s), 而在多個機(jī)器節(jié)點之間也可以配備基于RDMA技術(shù)的高速網(wǎng)絡(luò)設(shè)備,達(dá)到100-200Gbps的帶寬。選擇同步訓(xùn)練的第二個好處是可以利用高性能的集合通信算子庫(NVIDIA NCCL, 阿里自研的ACCL等)來有效地利用硬件機(jī)器的網(wǎng)絡(luò)拓?fù)浣Y(jié)構(gòu)來提升通信的性能,這些通信庫已經(jīng)在CV, NLP之類的基于數(shù)據(jù)并行的同步訓(xùn)練任務(wù)上取得了很好的效果。
使用資源異構(gòu)而角色同構(gòu)的訓(xùn)練單元
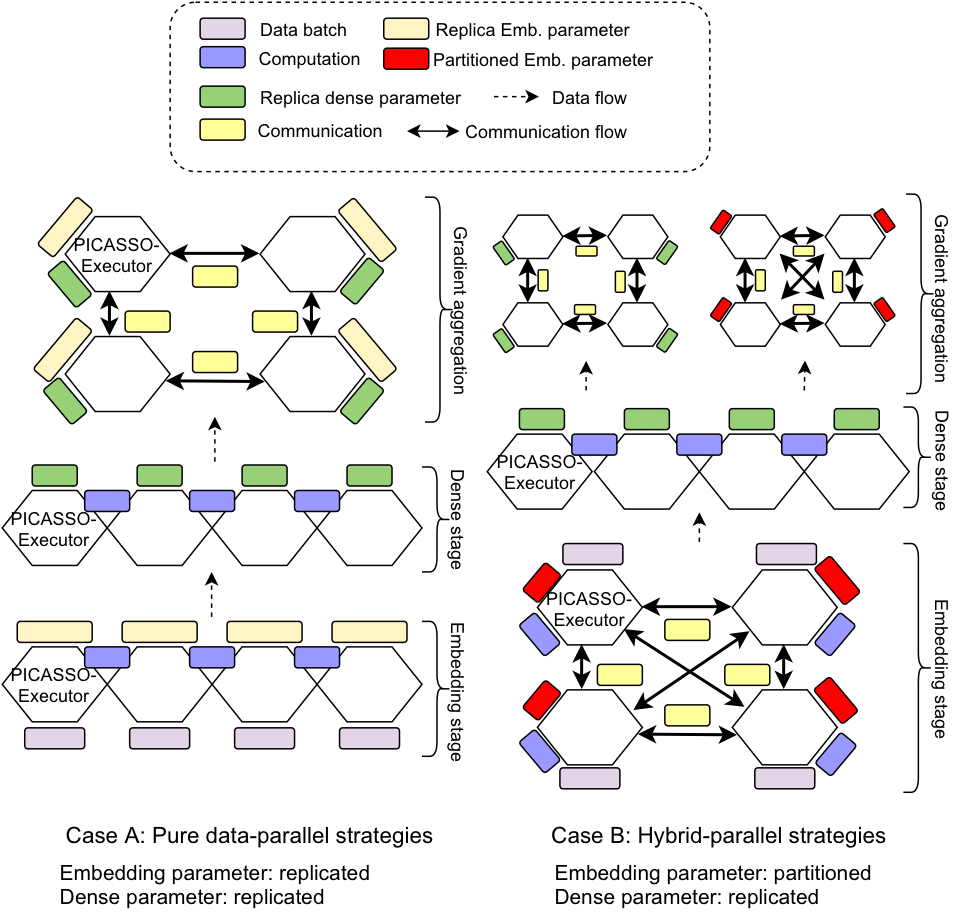
PS訓(xùn)練范式在系統(tǒng)的邏輯層面會指定不同的訓(xùn)練角色, 比如server, worker, evaluator。比如server節(jié)點一般分配具有大內(nèi)存的CPU機(jī)器,而worker節(jié)點則會被分配到高主頻的計算型CPU硬件上。這樣形成了訓(xùn)練單元-任務(wù)角色-同構(gòu)資源的耦合,通過增加訓(xùn)練單元數(shù)量來水平擴(kuò)展(scale out)訓(xùn)練的規(guī)模。而在高性能的GPU集群上,一個物理的機(jī)器節(jié)點往往包括多種異構(gòu)的硬件資源,如CPU, GPU處理器,GPU之間的高速互連,DRAM內(nèi)存,Non-volatile Memory等。這樣除了水平擴(kuò)展節(jié)點數(shù)量外,還可以通過垂直擴(kuò)展利用多種異構(gòu)硬件資源來達(dá)到擴(kuò)大訓(xùn)練規(guī)模的目標(biāo)。針對這種硬件架構(gòu),我們的系統(tǒng)設(shè)計中只保留統(tǒng)一的一種訓(xùn)練單元(Executor), 每個Executor通過內(nèi)部的異構(gòu)硬件資源來執(zhí)行不同的訓(xùn)練任務(wù)角色。一方面,Executor內(nèi)部任務(wù)執(zhí)行時可以有效地利用底層硬件資源之間的locality來加速訓(xùn)練,另一方面,Executor內(nèi)部的硬件資源可以同時滿足不同的分布式訓(xùn)練范式所需要的硬件資源,而方便我們在模型結(jié)構(gòu)的不同部分進(jìn)行混合的并行訓(xùn)練策略。
深入優(yōu)化:HybridBackend的技術(shù)亮點
在上述的系統(tǒng)架構(gòu)設(shè)計之下,因為稀疏模型結(jié)構(gòu)和訓(xùn)練數(shù)據(jù)本身的特性,階段性的資源需求變化和算子細(xì)碎化的問題還是會影響GPU等硬件設(shè)備的使用率。舉例來說,同步訓(xùn)練范式下所有Executor在通過集合通信進(jìn)行embedding的shuffle時,網(wǎng)絡(luò)帶寬資源成為瓶頸,而GPU的計算資源被閑置。一種解決思路是對硬件資源進(jìn)行定制化,比如增加網(wǎng)絡(luò)帶寬資源來消除通信瓶頸,但是這樣的做法會使得硬件的資源配置和特定的模型結(jié)構(gòu)耦合,是專用推薦系統(tǒng)的老思路。我們的目標(biāo)還是希望系統(tǒng)可以架構(gòu)在云服務(wù)上可得的,數(shù)量容易水平擴(kuò)展的通用硬件配置之上(commodity hardware)。某些硬件廠商也嘗試通過Huge kernel的形式(將Embedding層所有的計算手工融合到一個kernel內(nèi))來解決算子細(xì)碎化的問題, 這樣的做法也很難支持模型結(jié)構(gòu)快速迭代的需求, 背離了通用編程架構(gòu)的設(shè)計初衷。
據(jù)此,我們從軟硬協(xié)同的思路出發(fā),設(shè)計了如下的幾個系統(tǒng)優(yōu)化手段:
基于數(shù)據(jù)和算子感知的合并
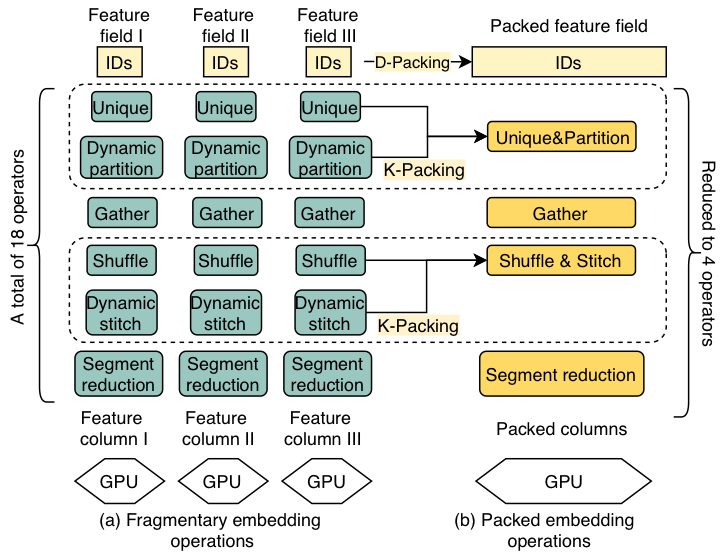
根據(jù)稀疏模型的結(jié)構(gòu)特點,大部分細(xì)碎的算子來源于龐大的Embedding特征查詢(lookup)數(shù)量,我們設(shè)計了D-Packing這一優(yōu)化技術(shù)。對于每一路查詢,盡管輸入的訓(xùn)練數(shù)據(jù)不同,但使用的算子組合是相同的。對于這種具有數(shù)據(jù)并行特點的模式,具有相同屬性(維度、初始化器、標(biāo)定特征組等)的Embedding表將被合并為一張新的Embedding表,而后后續(xù)的訪存查詢算子也可以被合并為一個新的大算子。合并算子可以用多線程的方式有序查詢Embedding,相對于亂序查詢或分成若干小表查詢,能有顯著的性能提升。查詢完畢后,再依原有代碼需要進(jìn)行反去重和歸位,真正做到了對用戶透明。此外通過分析特征查詢階段各個算子在分布式環(huán)境下的語義,我們將部分的kernel進(jìn)行融合K-Packing, 比如通過融合shuffle和stitch算子來消除冗余的數(shù)據(jù)拷貝。通過數(shù)據(jù)和算子兩個維度的基于語義的融合,我們既減少了總體的算子數(shù)量,降低fragmentation, 同時又避免了所有算子融合在一起而丟失了下文敘述的通過算子間穿插遮掩來提升硬件利用率的優(yōu)化機(jī)會。
基于硬件資源瓶頸感知的交錯執(zhí)行
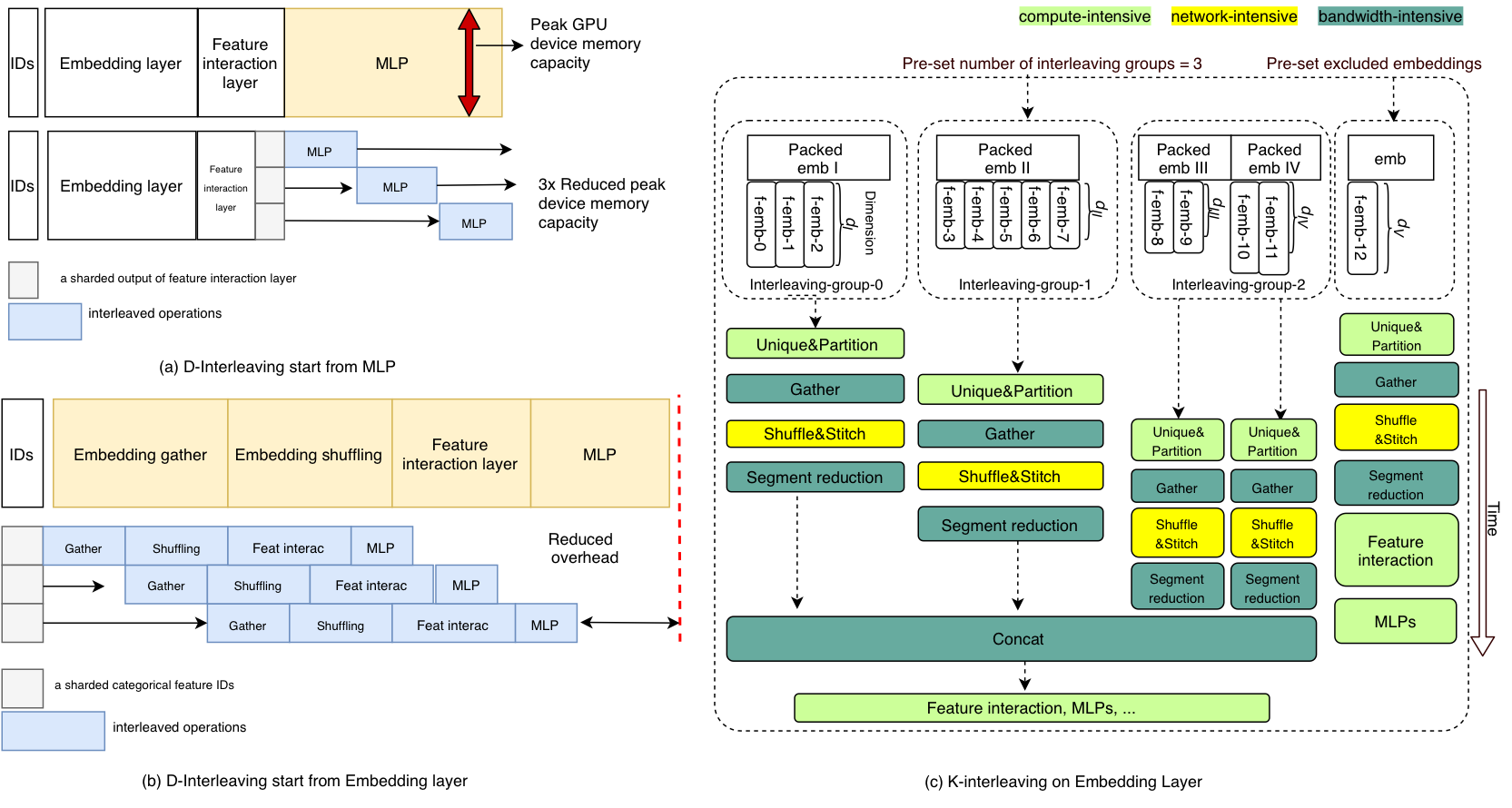
為了消除同時執(zhí)行相同硬件資源需求的算子而造成的瓶頸, 我們設(shè)計了兩種算子穿插遮掩執(zhí)行(interleaving)的優(yōu)化手段。1) D-Interleaving是通過對訓(xùn)練數(shù)據(jù)batch的切分利用pipeline的機(jī)制來調(diào)度穿插不同資源類型的算子,這樣可以在訓(xùn)練的任何階段緩解某一種資源的瓶頸。比如在大batch size的訓(xùn)練場景下,稀疏模型的MLP階段也會產(chǎn)生很高的feature map顯存占用,通過D-Interleaving就可以有效降低單個GPU設(shè)備上的峰值顯存占用,從而使得更大的batch size訓(xùn)練成為可能。2)K-Interleaving是在Embedding Layer內(nèi)部不同的特征查詢路數(shù)之間做算子的穿插和遮掩,比如將通信密集的Shuffle操作和內(nèi)存訪問密集的Gather進(jìn)行遮掩,可以有效提升這兩種資源的使用率。
基于數(shù)據(jù)頻次感知的參數(shù)緩存
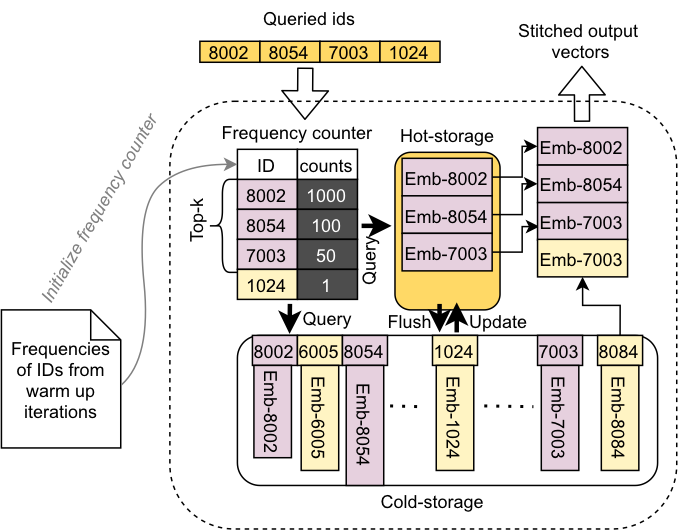
在解決Executor內(nèi)部多個級別的存儲(GPU顯存,DRAM等)之間的帶寬和延遲問題上,我們針對稀疏模型訓(xùn)練數(shù)據(jù)的分布特點,提出了一種感知數(shù)據(jù)訪問頻次分布的caching機(jī)制。通過統(tǒng)計訓(xùn)練數(shù)據(jù)的ID,將最熱的訪問數(shù)據(jù)緩存到GPU的顯存中,而冷數(shù)據(jù)以及哈希表結(jié)構(gòu)則存放在主內(nèi)存中,主內(nèi)存中的數(shù)據(jù)將根據(jù)ID的訪問頻率變化,定期將topk的高頻ID對應(yīng)的embeddings刷新到GPU顯存上的緩存中。這樣的混合存儲可以同時結(jié)合GPU顯存的高帶寬和DRAM的容量,后續(xù)這套混合存儲的設(shè)計還可以擴(kuò)展到包含Intel Persistent Memory, Non-volatile Memory等更多的硬件設(shè)備上。
業(yè)務(wù)落地
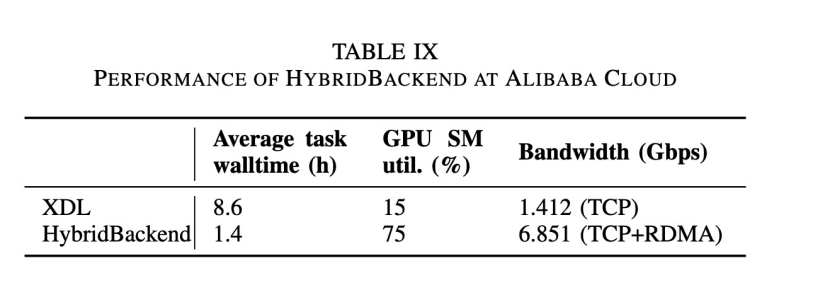
HybridBackend已經(jīng)成功在阿里媽媽智能引擎訓(xùn)練引擎團(tuán)隊定向廣告業(yè)務(wù)中有了落地,本文的實驗中也介紹了在阿里媽媽CAN模型下HybridBackend相對于上一代的XDL訓(xùn)練框架獲得的性能優(yōu)勢,在下表中可以看到在訓(xùn)練時長等多個指標(biāo)下獲得的顯著提升。
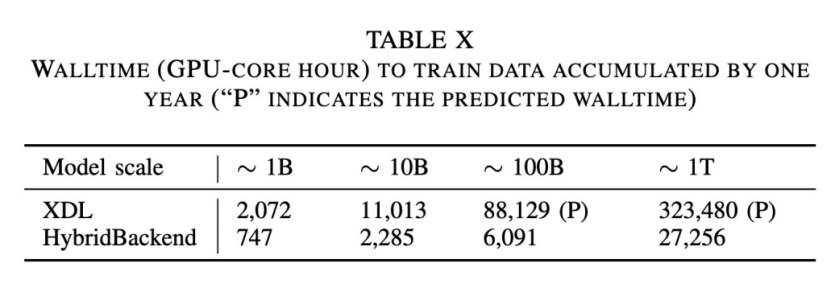
同時我們還以阿里媽媽定向廣告一年累計的訓(xùn)練數(shù)據(jù)上對模型的規(guī)模增長下的HybridBackend性能表現(xiàn)做了測試,結(jié)果如下表所示。可以看到在使用128張GPU進(jìn)行千億規(guī)模參數(shù)模型的訓(xùn)練時,同樣是消費1年的數(shù)據(jù)量,高性能集群上的HybridBackend僅僅需要2天的時間完成訓(xùn)練任務(wù),而普通集群上的XDL-PS模式則需要約1個月的時間。
參考文獻(xiàn)
[1] Oldridge, Even, Julio Perez, Ben Frederickson, Nicolas Koumchatzky, Minseok Lee, Zehuan Wang, Lei Wu et al. "Merlin: A GPU Accelerated Recommendation Framework." In Proceedings of IRS . 2020.
論文詳情
論文標(biāo)題:PICASSO: Unleashing the Potential of GPU-centric Training for Wide-and-deep Recommender Systems
論文作者: 張遠(yuǎn)行、陳浪石(并列一作)、楊斯然、袁滿、易慧民、張杰、王家忙、董建波、許云龍、 宋鉞、李永、張迪、林偉、曲琳、鄭波
論文鏈接: https://arxiv.org/abs/2204.04903
開源地址:https://github.com/alibaba/HybridBackend
HybridBackend用戶交流群,入群有專人解答,歡迎加入(釘釘群號):42494662
想了解更多AI開源項目,請點擊:
https://www.aliyun.com/activity/bigdata/opensource_bigdata__ai
星空人工智能技術(shù)網(wǎng) 倡導(dǎo)尊重與保護(hù)知識產(chǎn)權(quán)。如發(fā)現(xiàn)本站文章存在版權(quán)等問題,煩請30天內(nèi)提供版權(quán)疑問、身份證明、版權(quán)證明、聯(lián)系方式等發(fā)郵件至1851688011@qq.com我們將及時溝通與處理。!:首頁 > 新聞 » 阿里自研稀疏模型框架HybridBackend論文入選國際頂會ICDE 2022