近日,阿里云機器學習平臺PAI與香港大學吳川教授團隊合作的論文”Efficient Pipeline Planning for Expedited Distributed DNN Training”入選INFOCOM(IEEE International Conference on Computer Communications) 2022,論文提出了一個支持任意網絡拓撲的同步流水線并行訓練算法,有效減少大規模神經網絡的訓練時間。
作為分布式機器學習的一種主流訓練方式,流水線并行通過同時進行神經網絡計算與中間數據通信,減少訓練時間。一個典型的同步流水線并行方案包含模型切分設備部署與微批量(micro-batch)執行調度兩個部分。
以下的兩個圖給出了一個6層神經網絡模型在4塊GPU上進行同步流水線并行訓練的示例。由圖表1所示,模型被切分成三個片段,其中第二個片段由于其計算量較大,被復制到兩個GPU上通過數據并行的方式訓練。圖表2表示模型的三個微批量的具體訓練過程,其中,由于第二個片段以數據并行方法在GPU2和GPU3上訓練,在全部微批量訓練完成后通過AllReduce算子同步模型片段參數。
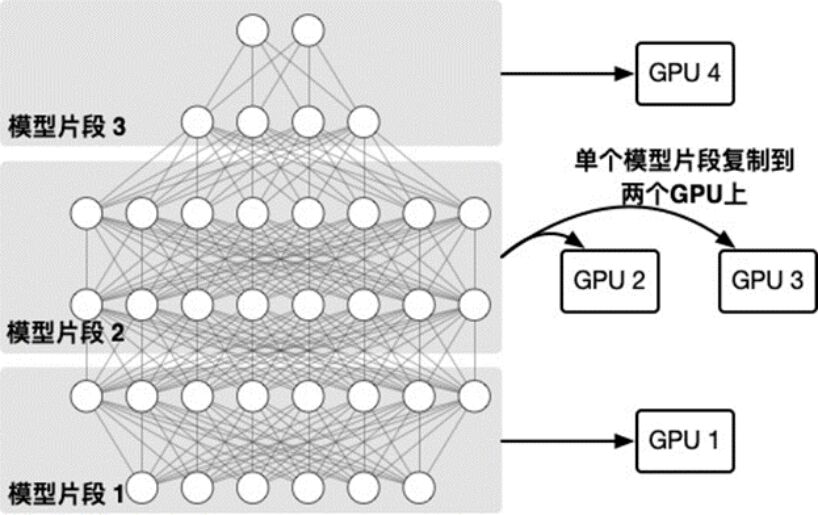
圖表1模型切分設備部署
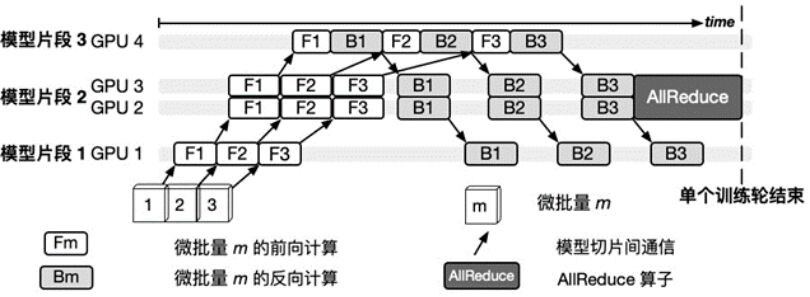
圖表2微批量執行調度
然而,設計高效的流水線并行算法方案仍然存在諸多挑戰,例如深度學習模型各異,每層的訓練時間也不相同,因此難以找到最優的模型切分部署方案;當前的流水線并行算法局限于同質化的GPU間網絡拓撲,而現實機器學習集群具有復雜的混合GPU間網絡拓撲(例如,單個機器上的GPU可以通過PCIe或者NVLink連接,跨機通信可以基于TCP或者RDMA),導致現有方案無法使用等,以上問題導致實際訓練中的GPU使用效率低。
針對以上難點,團隊提出了一個近似最優的同步流水線并行訓練算法。算法由三個主要模塊構成:
1) 一個基于遞歸最小割的GPU排序算法,通過分析GPU間網絡拓撲確定GPU的模型部署順序,保證最大化利用GPU間帶寬;
2) 一個基于動態規劃的模型切分部署算法,高效率找到最優的模型分割與部署方案,平衡模型在每個GPU上的運算時間與模型切片間的通信時間;
3) 一個近似最優的列表排序算法,決策每個微批量在各個GPU上的執行順序,最小化模型的訓練時間。
從理論上對算法做出詳盡分析,給出了算法的最壞情況保證。同時,在測試集群中實驗證明團隊的算法相對PipeDream,可以取得最高157%的訓練加速比。
INFOCOM是計算機網絡三大頂級國際會議之一,涉及計算機網絡領域的各個方面,在國際上享有盛譽且有廣泛的學術影響力。此次入選意味著阿里云機器學習平臺PAI在分布式深度學習模型訓練優化領域的工作獲得國際學界的廣泛認可,進一步彰顯了中國在分布式機器學習系統領域有著核心競爭力。
阿里云機器學習PAI是面向企業及開發者,提供輕量化、高性價比的云原生機器學習平臺,一站式的機器學習解決方案,全面提升機器學習工程效率。
星空人工智能技術網 倡導尊重與保護知識產權。如發現本站文章存在版權等問題,煩請30天內提供版權疑問、身份證明、版權證明、聯系方式等發郵件至1851688011@qq.com我們將及時溝通與處理。!:首頁 > 新聞 » 阿里云機器學習平臺PAI與香港大學合作論文入選INFOCOM 2022,有效減少大規模神經網絡訓練時間