作者:同潤、臨在
日前,中文語言理解權(quán)威評測基準(zhǔn)CLUE公布了零樣本學(xué)習(xí)ZeroCLUE的最新結(jié)果,阿里云位于該榜單榜首。此次刷榜的模型是阿里云機(jī)器學(xué)習(xí)PAI團(tuán)隊(duì)推出的160億參數(shù)的稀疏模型 GPT-MoE,這也是業(yè)界首個中文稀疏GPT大模型在該榜單登頂。
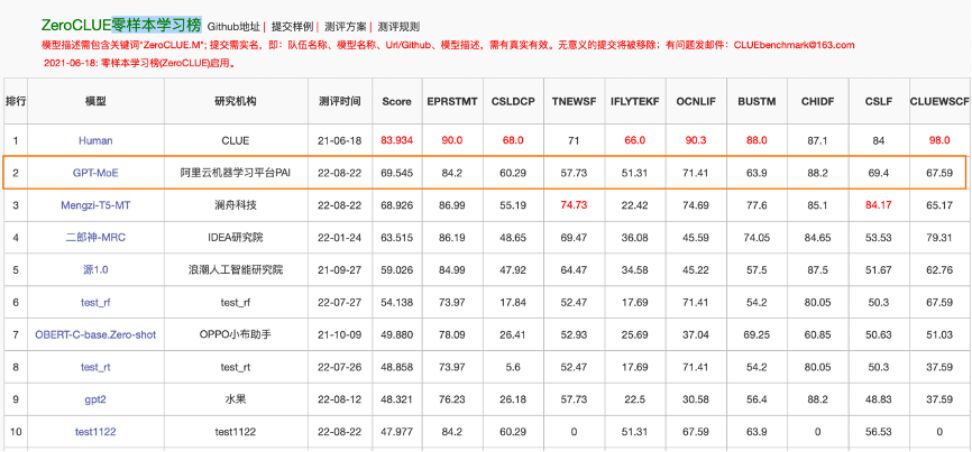
在繼去年的Transformer Encoder大模型取得中文小樣本學(xué)習(xí)、英文預(yù)訓(xùn)練模型知識量度量冠軍后,今年阿里云將大模型技術(shù)能力又向前推進(jìn)了一步。基于MoE稀疏結(jié)構(gòu),僅用一臺A100就把160億參數(shù)量級的多任務(wù)通用GPT模型訓(xùn)練成熟。這是通往低成本且高性能多任務(wù)通用自然語言理解的重要里程碑。
中文GPT大模型落地主要面臨來自兩方面的挑戰(zhàn):一方面是中文語言建模的困難,中文可以利用復(fù)雜多變的自由組合表達(dá)多重含義,這使得中文語言模型比英文在表達(dá)效率上難度加倍;另一方面隨著模型參數(shù)量的不斷增加,需要投入的硬件成本越來越高,訓(xùn)練成熟時間越來越長。
以O(shè)penAI推出的1750億的GPT-3為例,在1024張A100GPU上預(yù)估需要34天;因此,能否消耗更少的計(jì)算資源以高性價比的方式完成訓(xùn)練和推理是大模型落地亟待解決的難題。
GPT-MoE 模型采用稀疏模型的結(jié)構(gòu)設(shè)計(jì),有效緩解了上面提到的兩個困難。在刷榜的過程中,從工程到算法沉淀出4點(diǎn)自研核心技術(shù),有強(qiáng)化型稀疏均衡器,領(lǐng)域話術(shù)再適應(yīng)驅(qū)動的中文提示語零樣本學(xué)習(xí),中文復(fù)雜任務(wù)定向優(yōu)化,以及阿里云自主研發(fā)的transformer訓(xùn)練加速工具Rapidformer,實(shí)現(xiàn)了單機(jī)A100即可訓(xùn)練160億參數(shù)大模型。
目前,GPT-MoE 模型已在阿里云機(jī)器學(xué)習(xí)PAI EasyNLP項(xiàng)目中開源,和開發(fā)者共享中文百億稀疏GPT大模型技術(shù)。
開源項(xiàng)目地址:https://github.com/alibaba/EasyNLP/tree/master/examples/rapidformer
星空人工智能技術(shù)網(wǎng) 倡導(dǎo)尊重與保護(hù)知識產(chǎn)權(quán)。如發(fā)現(xiàn)本站文章存在版權(quán)等問題,煩請30天內(nèi)提供版權(quán)疑問、身份證明、版權(quán)證明、聯(lián)系方式等發(fā)郵件至1851688011@qq.com我們將及時溝通與處理。!:首頁 > 大數(shù)據(jù) » 阿里云推出單機(jī)即可訓(xùn)練百億參數(shù)的中文稀疏GPT大模型,登頂 ZeroCLUE零樣本學(xué)習(xí)榜單